

We’re excited to announce a tech preview of Cloudera AI Inference service powered by the full-stack NVIDIA accelerated computing platform, which incorporates NVIDIA NIM inference microservices, a part of the NVIDIA AI Enterprise software program platform for generative AI. Cloudera’s AI Inference service uniquely streamlines the deployment and administration of large-scale AI fashions, delivering excessive efficiency and effectivity whereas sustaining strict privateness and safety requirements.
It integrates seamlessly with our lately launched AI Registry, a central hub for storing, organizing, and monitoring machine studying fashions all through their lifecycle.
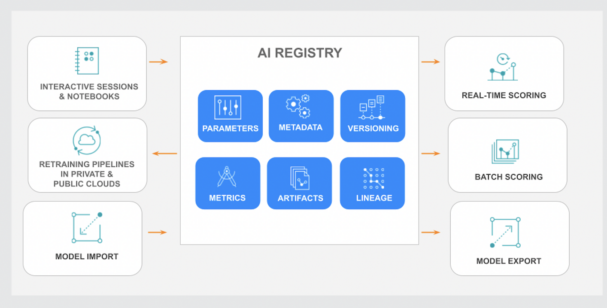
Cloudera AI Registry: Centralized Mannequin Administration
By combining the AI Registry with superior inference capabilities, Cloudera gives a complete answer for contemporary MLOps, enabling enterprises to effectively handle, govern, and deploy fashions of any dimension throughout private and non-private clouds.
The brand new AI Inference service affords accelerated mannequin serving powered by NVIDIA Tensor Core GPUs, enabling enterprises to deploy and scale AI purposes with unprecedented pace and effectivity. Moreover, by leveraging the NVIDIA NeMo platform and optimized variations of open-source LLMs like LLama3 and Mistral fashions, enterprises can make the most of the newest developments in pure language processing, pc imaginative and prescient, and different AI domains.

Cloudera AI Inference: Scalable and Safe Mannequin Serving
Key Options of Cloudera AI Inference service:
- Hybrid cloud assist: Run workloads on premises or within the cloud, relying on particular wants and necessities, making it appropriate for enterprises with advanced information architectures or regulatory constraints.
- Platform-as-a-Service (PaaS) Privateness: Enterprises have the flexibleness to deploy fashions straight inside their very own Digital Non-public Cloud (VPC), offering a further layer of safety and management.
- Actual-time monitoring: Acquire insights into the efficiency of fashions, enabling fast identification and backbone of points.
- Efficiency optimizations: As much as 3.7x throughput enhance for CPU-based inferences and as much as 36x sooner efficiency for NVIDIA GPU-based inferences.
- Scalability and excessive availability: Scale-to-zero autoscaling and HA assist for lots of of manufacturing fashions, making certain environment friendly useful resource administration and optimum efficiency underneath heavy load.
- Superior deployment patterns: A/B testing and canary rollout/rollback permit gradual deployment of recent mannequin variations and managed measurement of their influence, minimizing threat and making certain easy transitions.
- Enterprise-grade safety: Service Accounts, Entry Management, Lineage, and Audit options preserve tight management over mannequin and information entry, making certain the safety of delicate data.
The tech preview of the Cloudera AI Inference service gives early entry to those highly effective enterprise AI mannequin serving and MLOps capabilities. By combining Cloudera’s information administration experience with cutting-edge NVIDIA applied sciences, this service allows organizations to unlock the potential of their information and drive significant outcomes by generative AI. With its complete function set, strong efficiency, and dedication to privateness and safety, the AI Inference service is essential for enterprises that need to reap the advantages of AI fashions of any dimension in manufacturing environments.
To be taught extra about how Cloudera and NVIDIA are partnering to broaden GenAI capabilities with NVIDIA microservices, learn our latest press launch.